In this article I’m going to share an approach that we use to execute some long running background tasks for our project.
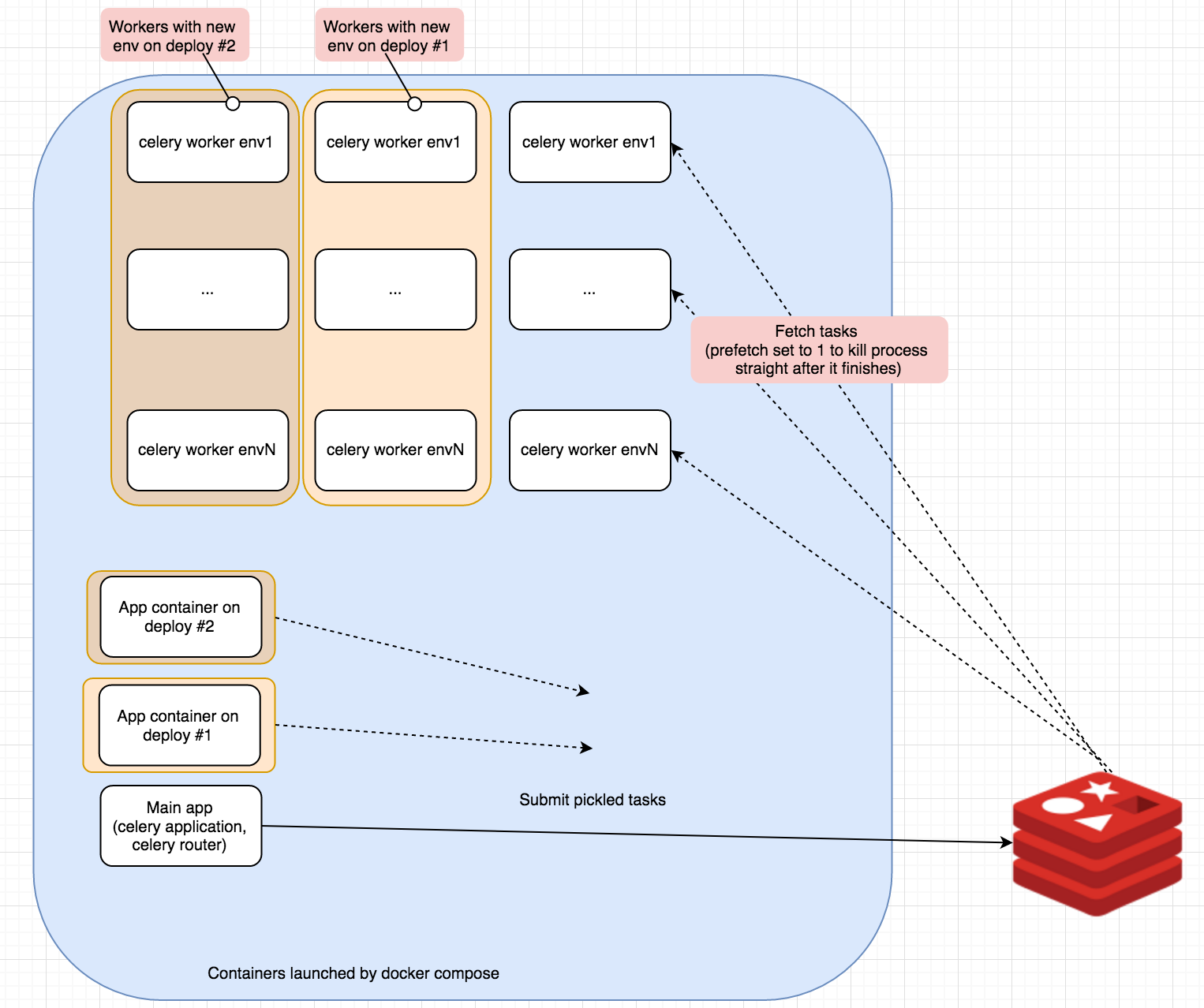
So I use Celery as a task executor with a Redis broker backend. I have couple of different environments for my workers so each of those runs within docker container. We want to support hot reloading too. For example we have our environment changed and that would require building new images and running workers within this new environment. At the same time we want currently running processes to finish without any interruptions and new task submitted to be picked up by new workers.
Current implementation
Right now I have following pipeline
On each requirements change of dockerfiles change we trigger new jenkins build that will create images with new environment
Tag for the image is created dynamically based on a hash sum from from requirements
On each deploy (we use Ansible for that) we render docker-compose files with corresponding image tags
At this point we have our workers running with the new envrionment
So, what’s left? We need to gracefully kill all previous workers and dynamically route new tasks to new workers. But first things first.
defget_requirements(filename): """ Gets requirements from a file ignoring comments and extra data. """ return [str(r.req) for r in parse_requirements(filename, session='')]
defget_current_project_requirements(): """ Returns all requirements for the project as a string each requirement per new line. """ project_requirements = [] for filename insorted(glob.glob('requirements/*.txt')): project_requirements.extend(get_requirements(filename))
return'\n'.join(project_requirements)
defget_current_image_tag(): """ Based on hash of all the requirements files return a tag for latest docker images. """ all_reqs = get_current_project_requirements() image_tag = get_requirements_hash(all_reqs) return image_tag
In this example we get all the *.txt files in requirements directory but it can be any text file as long as get_current_project_requirements will be consistent about its results (notice sorted function to make sure that we will always have same order for the lines therefore the same hash for identical requirements).
Our custom router needs to implement route_for_task method which will tell based on parameters provided the right queue we need. There is a safe callback that would be redirecting to latest queue in case no active queue for the current version was found. You can actually omit this and just fail with an error at this point.
Here’s an example of dictionary-based config but you can provide your configuration in the usual way you used to.
Now on deploys we need to stop consuming tasks on queues with previous tags allowing them to finish in orphaned containers. I invoke ansible task with following python script for that.
1 2 3 4 5 6 7 8 9 10 11
from celery_tasks import celery_app from utils import get_current_image_tag
defstop_consuming(): consumers = ('v1', 'v2', 'vN', 'latest') current_tag = get_current_image_tag() for consumer in consumers: consumer_queue = '{}-{}'.format(consumer, current_tag) print('Stopping workers from listening on queue {}'.format(consumer_queue)) celery_app.control.cancel_consumer(consumer_queue)
And then we just launch docker compose with a compose file created from such a template
This approach works fine for us but we still have all the workers running on the same node with a broker itself. In order to scale this solution I suggest using RabbitMQ as a broker and distribute workers across multiples nodes (e.g. by the version), hopefully Ansible also allows to use multiple hosts. The only issue we have is some delay needed to build new images in order to launch integration tests with new images but anyway it’s worth it.