Monitoring Celery queue with Datadog

Sometimes your Celery workers are having hard time processing all the tasks from a queue. It might be due to your tasks being long running or due to a high load on workers themselves. Obviously you need to consider autoscaling in order to handle this issue but in a first place you need to know is something going wrong. For this purpose we will setup monitoring with Datadog platform. The easiest way to know when your queue is getting bigger is by restricting your workers of fetching more than one task at once (set prefetch limit to 1: pass --prefetch-multiplier=1 when launching your worker). This way tasks would be hanging in a queue if no worker is able to process it and therefore it will be easy to monitor queue size.
I’m assuming that you have already installed datadog agent and you are using Redis as a broker. Celery will create a list for your queue with a key named after your queue name (default one is celery in case you do not have an extra routing). The only thing you need to do is to create a file with content
1 | init_config: |
and place it at the /etc/datadog-agent/conf.d/redisdb.d/conf.yaml destination. Now restart agent and verify check was discovered and works properly
1 | $ sudo service datadog-agent restart # restart agent |
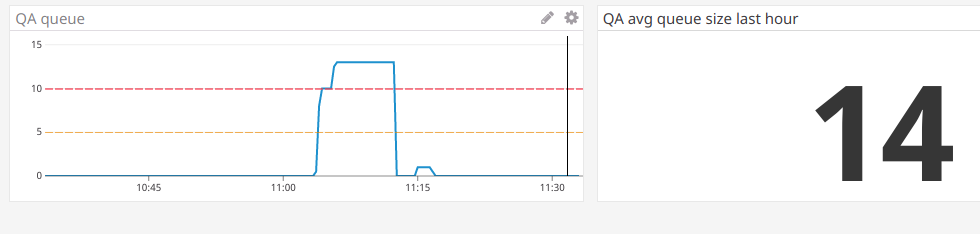
Now go to you Datadog dashboard and add new timeseries chart for redis.key.length metric.
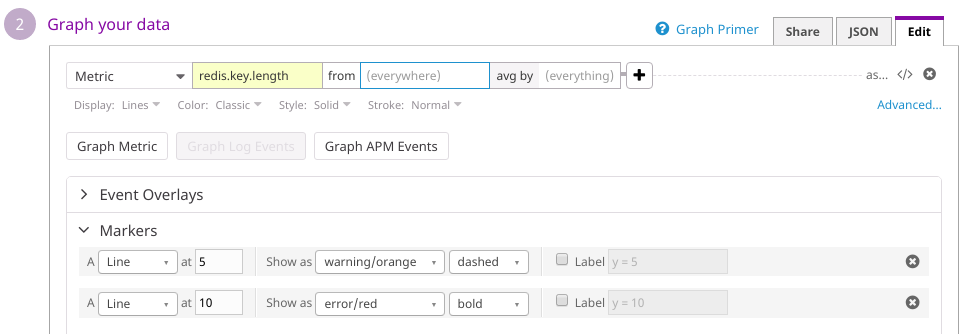
Specify error/warning thresholds according to number of workers available. Ideally queue size should not grow at all, so do not set this value higher than 20. Finally you should set up a monitor for the same metric and send notifications to email/messengers when queue is bigger than it should be.
Update for Ansible users
In case you need to add monitoring to multiple instances and you are using Ansible to provision your infrastructure you can add just one task that will automate all the thing for the process above.
1 |
|
Now you can feel a bit relaxed and think about optimizing/refactoring your tasks and scaling infrastructure for workers. Do not forget to add other tools for Celery monitoring such as Flower!